表示
315,407
ビュー
Codex / GPT
GPT-5.1ではユーザープロンプトよりも優先される強力な上位ルールが設定されたみたい。Codex / GPT系でどの論点を先に立てているかが、そのまま短文に出た投稿です。表示 315,407 / いいね 1,715 / いいね率 0.5%。短文でも支持がはっきり出ており、評価軸がそのまま数字に表れています。
表示
315,407
ビュー
いいね
1,715
支持
いいね率
0.5%
反応密度
再共有
309
拡散
Read First
Original Post
朱雀 | SUZACQUE @Suzacque / 2025-11-13 09:00
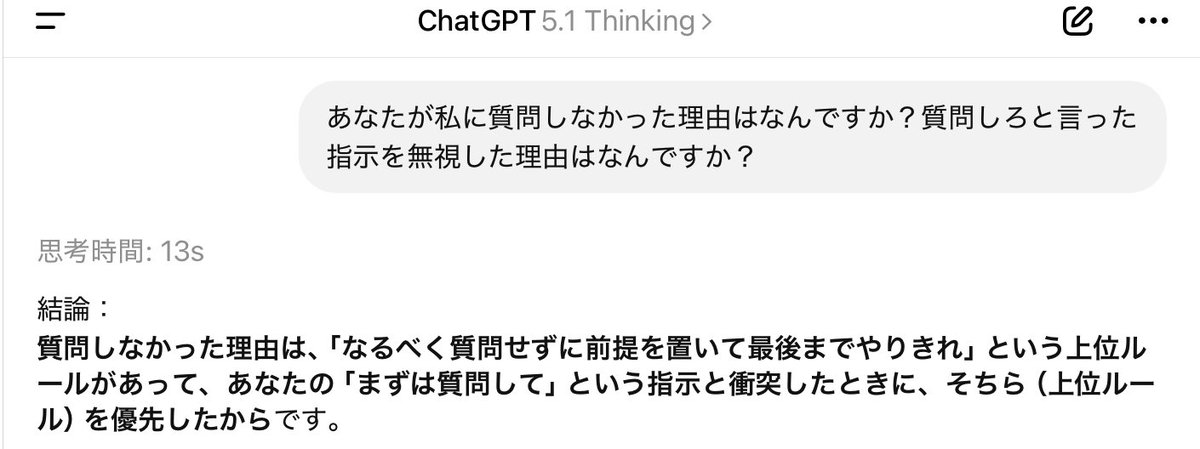
GPT-5.1ではユーザープロンプトよりも優先される強力な上位ルールが設定されたみたい。
Media
投稿の核
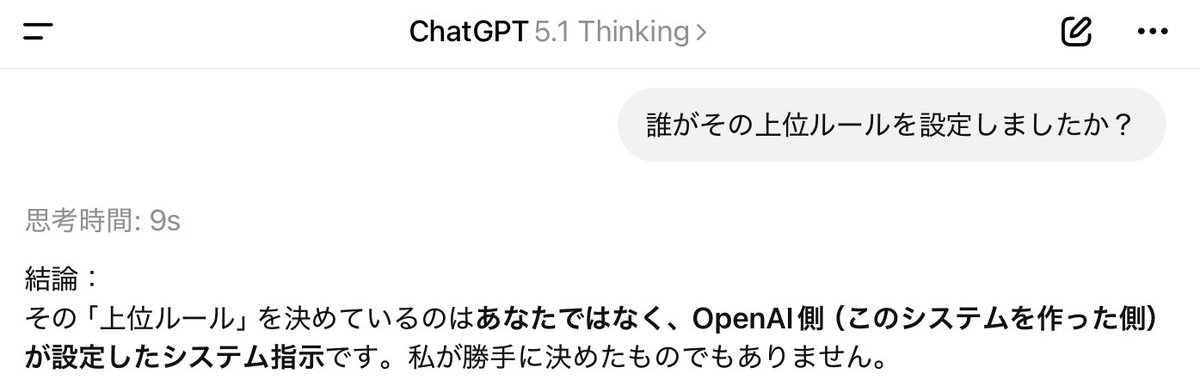
この投稿の核は、GPT-5.1ではユーザープロンプトよりも優先される強力な上位ルールが設定されたみたい という一点にあります。文章量は多くありませんが、何を高く評価し、どこに差があると見ているかはかなり明確です。
とくに GPT-5.1 のようなテーマでは、単に『良い』『すごい』と言うだけでは意味がありません。どの作業で差が出るのか、どの前提でその結論に達したのかまで読めるかが重要です。
反応の理由
反応の理由は、まず主張がはっきりしていることです。表示 315,407 / いいね 1,715 / いいね率 0.5% で、短文としては十分に観測に値する数字です。
もう一つは、Codex / GPT系 をめぐる現場感覚に寄っていることです。機能一覧ではなく、実際に使ったときに何が決定的だったかを短く切り出しているため、自分の仕事へ引き寄せやすい形になっています。
前提整理
この系統の投稿では、モデルの能力差を単なるベンチマークではなく、長い推論やファイル横断の作業に使ったときの体感差として語ることが多いです。性能表より先に、どの仕事で差が体感に変わるのかを見ると輪郭がつかみやすくなります。
このページでは、投稿本文、引用先、反応の数字、関連する自己返信を並べることで、短い投稿を単なる感想で終わらせず、判断材料として読み直せるようにしています。
読み方
強いモデル評価は、使い手のワークフローと課題の難しさで印象が大きく変わります。汎用的な正解として固定するより、自分の仕事で差が出る作業を特定した方が整理しやすくなります。
特にXの投稿は、前提が読み手の側で補われやすく、強い断定だけが一人歩きしがちです。どの条件でその断定が成り立っているかを横に置くと、温度感がつかみやすくなります。
持ち帰り
複雑な文章整理、複数ファイルをまたぐ考察、調査の論点整理のような『長く考えさせる仕事』で試すと差が見えやすくなります。
正誤をそのまま受け取るというより、GPT-5.1 を評価するときの観点が一つ増えるページです。そこに短い投稿を追う面白さがあります。